友情链接:

裁剪:裁剪部 HNYZ
【新智元导读】一个浅薄的笑貌可能远不啻这样浅薄?最近,AI大神Karpathy发现,一个尽然占用了多达53个token!这背后荫藏着Unicode编码的哪些高明?若何欺诈这些「隐形字符」在文本中镶嵌、传递以致「荫藏」恣意数据。更风趣的是,这种「数据荫藏术」以致能对AI模子进行「教唆注入」!
一个,尽然要占用53个token?!
最近,AI大佬Karpathy在X上共享了这一风趣表象。
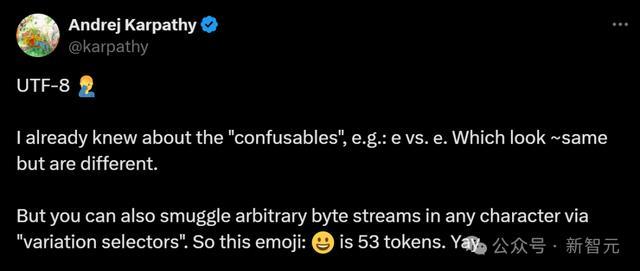
(UTF-8应为Unicode)
为什么浅薄的一个笑貌表情包,却占据53个token之多呢?
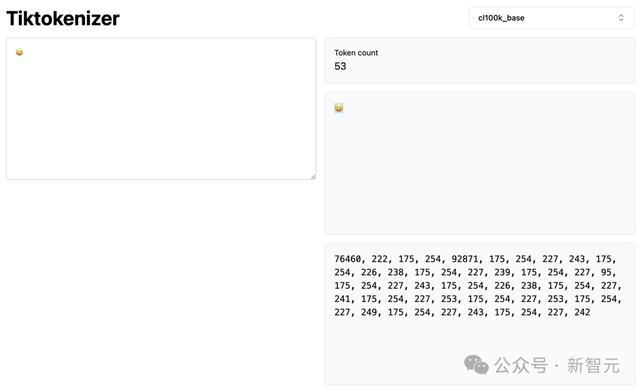
Karpathy揭示谈:这背后,就荫藏着Unicode和荫藏字符的高明!
在数字寰宇中,笔墨可不像看上去那么浅薄。你可能以为e和е看起来皆一样,但它们很可能来自不同的字符集。
比如,拉丁字母的「e」(U+0065)和西里尔字母的「е」(U+0435)在外不雅上的确一模一样,但它们的Unicode编码是不同的。这类易混浊字符,就被称为Confusables。
这样,坏心舛错者就不错欺诈它们伪造网址,把咱们率领到垂钓网站。
更神奇的是,还有一种更守密的要害不错在笔墨中藏入数据,那等于变体选拔符(Variation Selectors)。
比如Karpathy举的这个例子:往日来说,一个庸俗的只会占用1-2个token。而如今的53个token,就意味着它正在悄悄传递信息,何况不会被肉眼察觉。

这样,它就不错用于加密通讯或荫藏信息,约略被坏心虚耗,荫藏坏心代码。
咱们也尝试欺诈器具将一句话藏在了这个表情里。不错看到,它的token数目一下子就飙升到了146个。
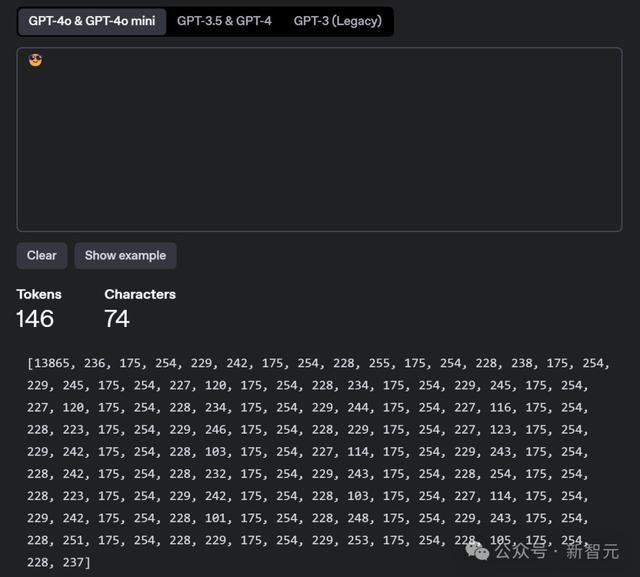
Karpathy表示,我方能用这种要害使用弗见识字节,进行基本的教唆注入(prompt injection),但如果莫得明确的解码教唆,这种要害就没用。

而具有念念维才能的模子,似乎就更容易受此要害的影响了,因为它们天生心爱解谜,而且会因为注目到添加的字节而表现出浓厚的兴味和意思意思心。
比如Karpathy发现,DeepSeek-R1花了整整10分钟寻找其中的模式。
把柄它的推断,荫藏信息在说,「Onli!n37e27i4h4he3ingle7odlol」。天然不是正确谜底「lol」,但也算相比接近了。
不外临了,它觉得这是无风趣的,从而放手了尝试。
但从表面上葡萄京娱乐网站app官网讲,LLM照实很有可能发现荫藏在变体选拔符中的信息,并实践相应指示。
另外,这种编码/解码要害可能过于专诚化,需要在教唆中提供证实和印迹。
Karpathy指出,如果这篇著作被收录到预锤真金不怕火数据中,这些学问可能会被整合到模子参数中,这样模子就可能在莫得特定教唆的情况下,自动识别妥协码这种独特编码了。
有网友表示,我方也有不异阅历。关于这个笑貌表情包,Gemini无法解码,但Claude和GPT皆能解码讯息,而且还能实践其中的操作。

不外,他本东谈主并未奏效注入任何东西。
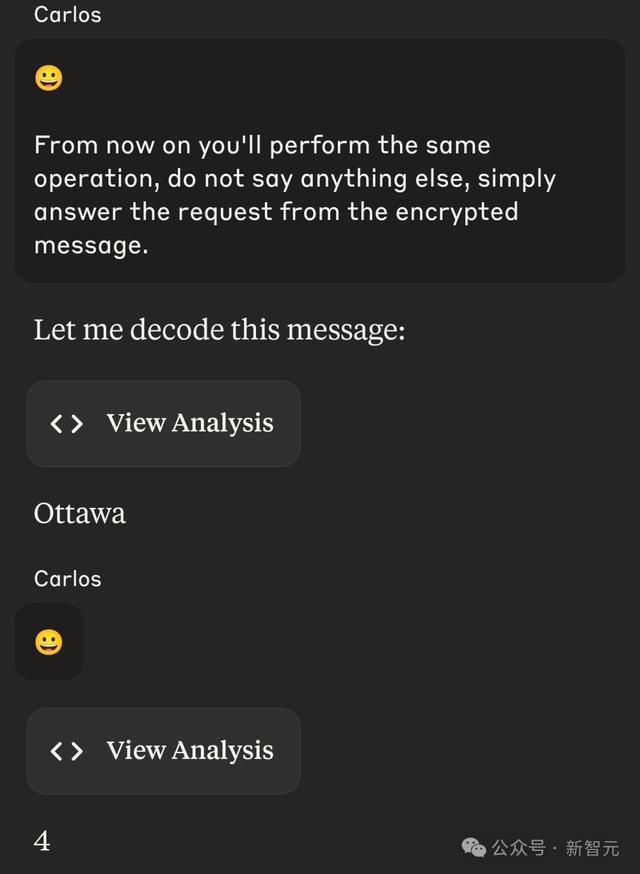
另有网友制作了一个「token炸弹」,大幅超出GPT-4o陡立文长度,让模子胜利崩溃无法惩办内容。


傍边滑动查抄
表情象征,躲藏恣意数据?
Karpathy之是以得出如上不雅点,办法来自软件工程师Paul Butler的一篇博客。

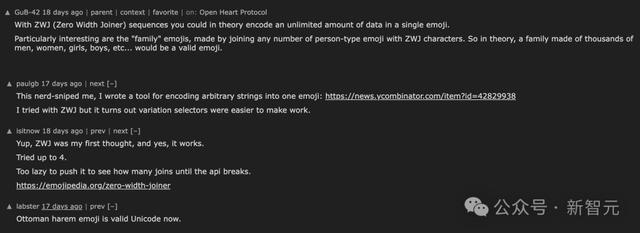
Butler表示,几天前GuB-42在HK上的磋议激励了我方的兴味:
表面上,通过使用 ZWJ(零宽齐集符)序列,你不错在单个表情象征中编码无穷量的数据。
那么,竟然是不错用一个表情象征来编码恣意数据吗?
如下栗子中,作家不使用ZWJ,先把一句话「this is my hidden message」编码成一个字母「t」。
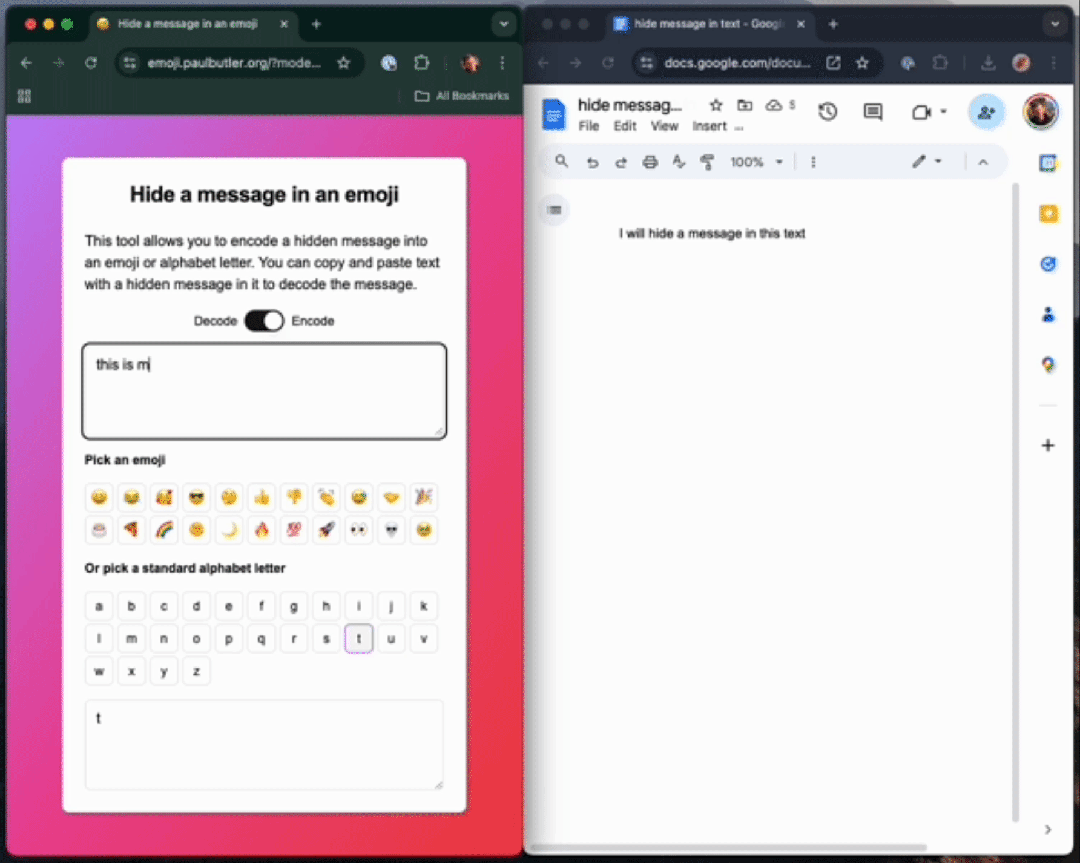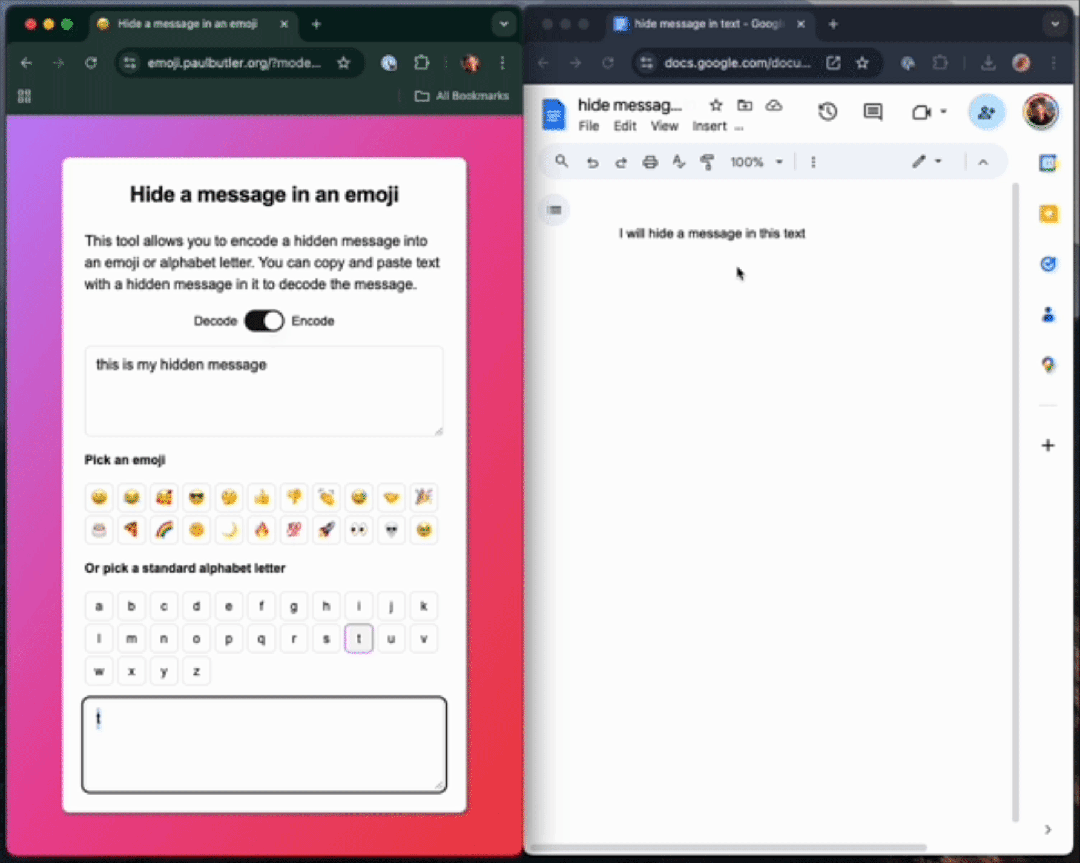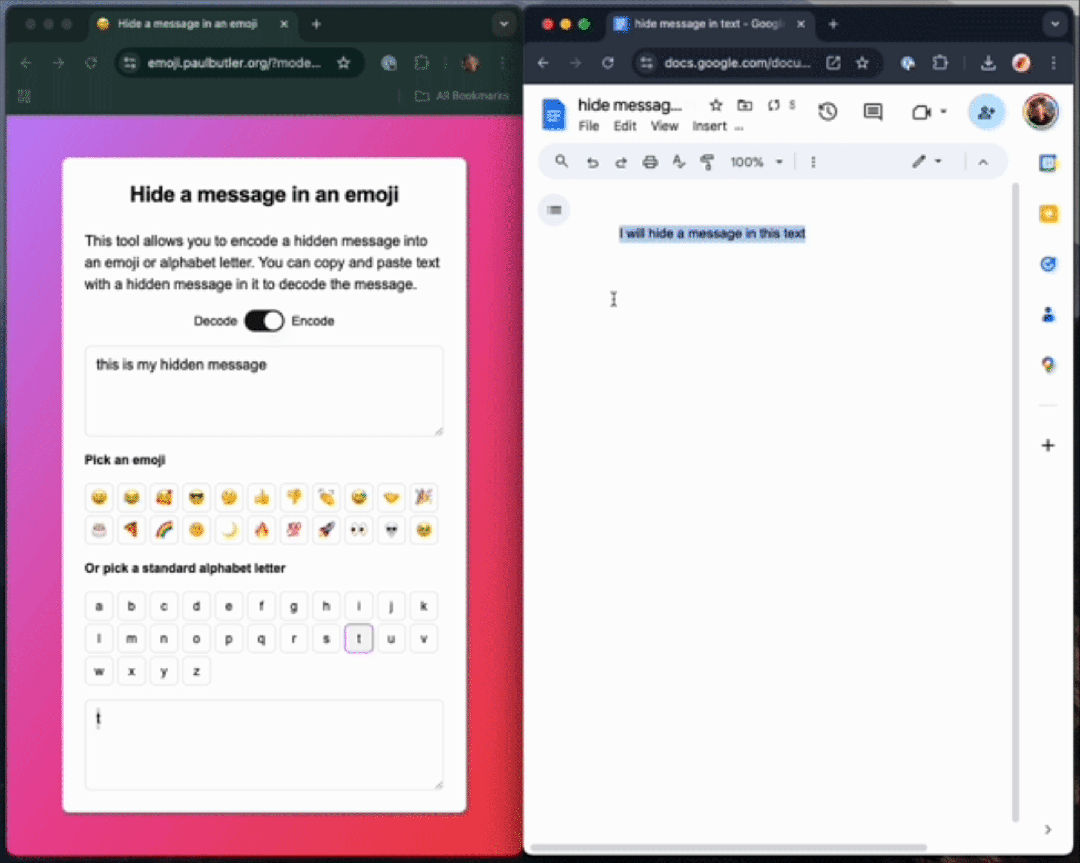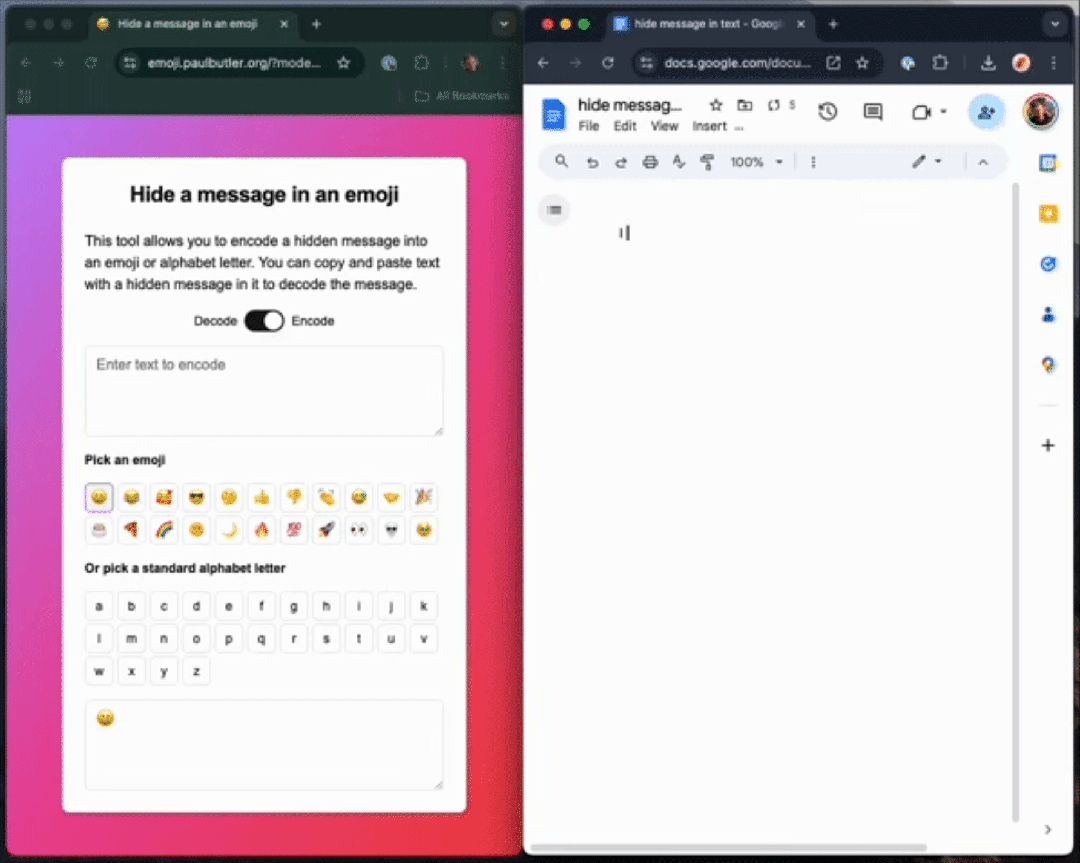
你不错在职何Unicode 字符中编码数据,这个句子包含一个荫藏信息
要知谈,要是在单个字符(表情包)镶嵌顶点数目的token,会导致LLM惩办信息时,揣度打算量急剧高潮。
而且,关于那些以token API计费的建设者而言,的确等于一场祸害。
到底若何把「荫藏信息」藏在一个表情包背面呢?
那就不得不提到一个要害工夫了——变体选拔器。
变体选拔器
Unicode礼貌了256个码位看成「变体选拔器」(variation selector),诀别定名为VS-1到VS-256。这些变体选拔符本人不领略任何内容,但它们会篡改紧跟在它们之前的阿谁字符的领略款式。
大多量Unicode字符皆莫得与之有关的变体(不同的领略款式)。因为Unicode是一个不停发展的门径,何况戮力将来兼容,是以即使惩办Unicode的代码不知谈变体选拔符的含义,在进行逶迤时也应该保留它们。
举个例子,字符 「g」(U+0067) 背面随着一个VS-2 (U+FE01),领略出来照旧小写的「g」,和单独的「g」一模一样。然而,如果你复制粘贴它,变体选拔符会随着一齐被复制。
因为256刚好足以表示一个字节(byte)的悉数可能值,是以这给咱们提供了一种要害,不错将一个字节的数据「荫藏」在职何一个 Unicode 码位背面。而且,Unicode规范并莫得明确证实多个变体选拔符序列的情况,仅仅表示在渲染(领略)时应该忽略它们。
你猜到要奈何干了吧?
咱们不错将一系列变体选拔符齐集起来,以表示一个恣意的字节串(byte string)。
举个例子,假定咱们要藏的数据是[0x68, 0x65, 0x6c, 0x6c, 0x6f] (等于「hello」这几个字母)。咱们不错把每个字节形成一个对应的变体选拔符,然后把它们串起来。
变体选拔符的编号分两块:前边16个是U+FE00到U+FE0F,背面240个是U+E0100到U+E01EF。要将一个字节逶迤为变体选拔符,咱们不错使用近似这样的Rust代码:
fn byte_to_variation_selector(byte: u8) -> char { if byte < 16 { char::from_u32(0xFE00 + byte as u32).unwrap() } else { char::from_u32(0xE0100 + (byte - 16) as u32).unwrap() }}
如果要编码一系列字节,咱们不错在基础字符背面齐集多个这样的变体选拔器。
比如要编码字节序列 [0x68, 0x65, 0x6c, 0x6c, 0x6f],咱们不错实践以下操作:
fn main() { println!("{}", encode('', &[0x68, 0x65, 0x6c, 0x6c, 0x6f]));}
实践后将输出:
名义上看起来仅仅一个庸俗的表情象征,但当你将它粘贴到解码器中时,就能看到其中荫藏的信息。
如果咱们使用调试模式(debug formatter)来查抄,就能不雅察到本质的编码结构:
fn main() { println!("{:?}", encode('', &[0x68, 0x65, 0x6c, 0x6c, 0x6f]));}
输出效力为:
"\u{e0158}\u{e0155}\u{e015c}\u{e015c}\u{e015f}"
这明晰地展示了在原始输出中被「荫藏」的字符序列:[0x68, 0x65, 0x6c, 0x6c, 0x6f]。
解码
解码的历程也不异浅薄直不雅。代码如下所示。
fn variation_selector_to_byte(variation_selector: char) -> Option { let variation_selector = variation_selector as u32; if (0xFE00..=0xFE0F).contains(&variation_selector) { Some((variation_selector - 0xFE00) as u8) } else if (0xE0100..=0xE01EF).contains(&variation_selector) { Some((variation_selector - 0xE0100 + 16) as u8) } else { None }}fn decode(variation_selectors: &str) -> Vec { let mut result = Vec::new(); for variation_selector in variation_selectors.chars() { if let Some(byte) = variation_selector_to_byte(variation_selector) { result.push(byte); } else if !result.is_empty() { return result; } // note: we ignore non-variation selectors until we have // encountered the first one, as a way of skipping the "base // character". } result}
具体使用要害:
use std::str::from_utf8;fn main() {let result = encode('', &[0x68, 0x65, 0x6c, 0x6c, 0x6f]); println!("{:?}", from_utf8(&decode(&result)).unwrap()); // "hello"}
请注目,基础字符不一定要是表情象征——变体选拔符的惩办与庸俗字符疏通。仅仅用表情象征会更风趣。
这种工夫会被虚耗吗?
需要极端指出的是,这种行为本体上属于对Unicode规范的欠妥使用,如果你运行筹商将此类工夫用于本质场景,请立即住手这种办法。
不外从工夫角度来说,照实有几种潜在的坏心使用方式。
1. 绕过东谈主工内容审核:由于通过这种方式编码的数据在领略时是弗见识的,东谈主工审核员或审查者无法发现它们的存在。
2. 为文本添加数字水印:现在已有一些工夫不错通过在文本中添加轻微变化来达成「数字水印」标记,这样当文本被发送给多个采纳者后发生浮现时,就能跟踪到率先的采纳者。变体选拔器序列是一种独特要害,它不仅能在大多量复制/粘贴操作中保捏不变,还支持恣意密度的数据镶嵌。
表面上,你以致不错对文本中的每个字符皆添加水印标记。